In this post, I want to talk about the connection between the Rank-Nullity Theorem from Linear Algebra and the First Isomorphism Theorem, which comes up in Abstract Algebra. We talked about the Rank-Nullity Theorem in the last post, but here’s a quick overview.
The Rank-Nullity theorem relates the dimension of the column space of an 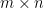 matrix
matrix  to the dimension of the null space of that matrix. Specifically, it says that the sum of these two values is equal to the number of columns of . That is,
to the dimension of the null space of that matrix. Specifically, it says that the sum of these two values is equal to the number of columns of . That is, 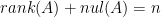 .
.
Before we talk about the First Isomorphism Theorem and relate it to linear transformations, let’s just define a few things that we’ll need to know to understand it.
Definition 1: The kernel of a transformation  is the set
is the set  . Note that
. Note that  .
.
Note that the kernel is a generalization of the null space of a matrix that is defined for both linear and nonlinear transformations.
Definition 2: An element  is in the image of a transformation if there exists some
is in the image of a transformation if there exists some 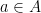 such that
such that  .
.
The image of a transformation is a generalization of the column space that holds for both linear and nonlinear transformations. That is, the image of matrix transformation is the column space of that matrix.
Definition 3: A group homomorphism from  to
to  is a function
is a function  such that for all
such that for all  and
and  in
in  , it holds that
, it holds that 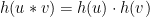
A good way to think about a group homomorphism is that it’s a transformation between groups that maintains the relationship between the groups elements. You will get the same result if you multiply two elements in and apply the function  as if you apply the function to them both separately and then multiply the two outputs in the group
as if you apply the function to them both separately and then multiply the two outputs in the group  together. This is interesting because the group composition rules are not necessarily the same.
together. This is interesting because the group composition rules are not necessarily the same.
Now, let’s state the specific case of First Isomorphism Theorem we’ll talk about.
First Isomorphism Theorem: Let 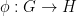 be a surjective homomorphism. Then, is isomorphic to
be a surjective homomorphism. Then, is isomorphic to  . Since
. Since  is surjective,
is surjective,  .
.
Hold on…What’s does mean? That notation is a quotient group. There is a formal definition of it, but for now, let’s think about it as a way to separate elements in into classes (called cosets) depending on their relationship with 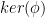 . This quotient group will have two cosets: one containing everything in that IS IN and one containing everything in that IS NOT IN .
. This quotient group will have two cosets: one containing everything in that IS IN and one containing everything in that IS NOT IN .
Because of the way quotient groups work, if goes between spaces of the same dimension, the original group can be written as the union of two sets: 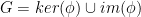 .
.
Since can be written in this way, it must be true that the size of is equal to the sum of the sizes of and  .
.
What does this say about linear transformations represented by square matrices? Since you can’t both be in a set AND not be in a set, it says that for a linear transformation from 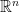 to , the null space and column space must be disjoint (except they’ll both have the zero vector in them).
to , the null space and column space must be disjoint (except they’ll both have the zero vector in them).
Let’s look at a few examples and see why this makes sense.
Example: Let  be an
be an 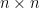 invertible matrix. This means that the columns map onto and also that the null space has only the zero vector, meaning that these two sets share only the zero vector.
invertible matrix. This means that the columns map onto and also that the null space has only the zero vector, meaning that these two sets share only the zero vector.
Example: Consider the non-invertible matrix  , which has the vector
, which has the vector 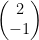 in its null space. If you try to solve
in its null space. If you try to solve  , you won’t be able to!
, you won’t be able to!
So, what have we learned? The First Isomorphism Theorem generalizes the Rank-Nullity Theorem in a way that lets us handle transformations between groups that are not necessarily Euclidean spaces. There is a tradeoff between having elements in the kernel of a transformation and elements in the image of a transformation. The larger the kernel is, the smaller the image is, and vice versa.
Let’s talk about the progression of these three theorems. The Invertible Matrix Theorem draws connections between the algebraic properties of a square matrix to the geometry of the transformation it represents. The Rank-Nullity theorem makes claims about the geometry of transformations between Euclidean spaces with potentially different dimensions. And the First Isomorphism Theorem makes claims about transformations between groups in general (note that and 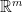 are groups for any integers
are groups for any integers  and
and  ).
).
In the next post, we’ll talk more about what the First Isomorphism Theorem is actually saying and a neat application of it to transformations between different dimensions.
Stay tuned!

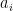

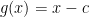
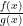
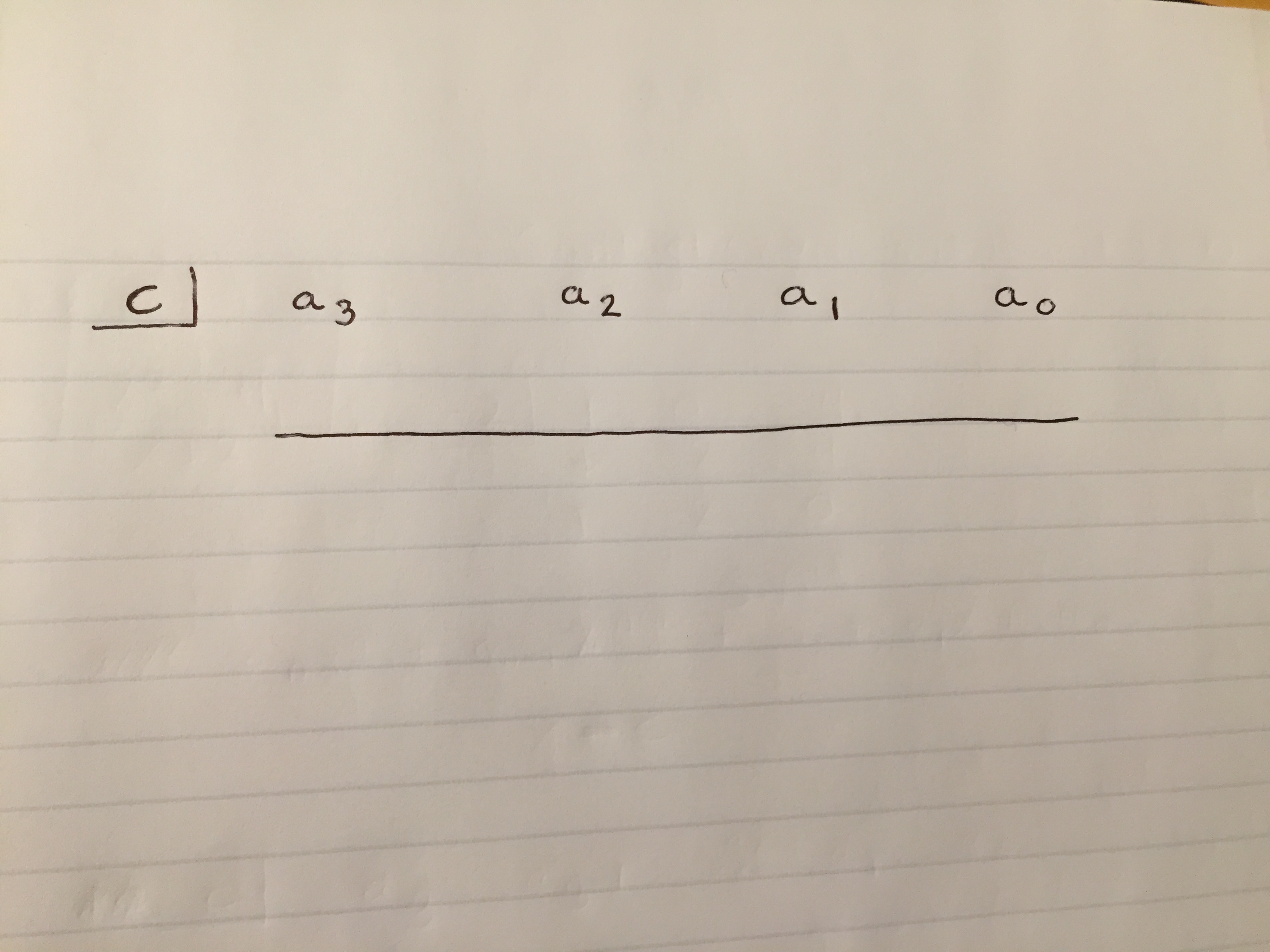



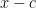


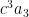





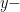


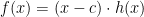


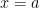






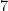

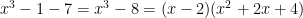
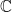 , then the polynomial will have
, then the polynomial will have  values that make the polynomial equal zero. Wouldn’t it be nice if there were a way to know where these zeros were?
values that make the polynomial equal zero. Wouldn’t it be nice if there were a way to know where these zeros were? has any rational zeros, then they will have to occur at
has any rational zeros, then they will have to occur at  , where
, where  is some factor of
is some factor of  and
and 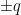 is some factor of
is some factor of  .
. , where the “
, where the “ ” includes the product of other linear terms. First, let’s find the zeros of this function. To do that, we want to solve
” includes the product of other linear terms. First, let’s find the zeros of this function. To do that, we want to solve  . Note that we won’t always be able to get
. Note that we won’t always be able to get 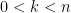 . The highest degree term comes from multiplying all of the terms that have an
. The highest degree term comes from multiplying all of the terms that have an  . And the lowest degree term will be
. And the lowest degree term will be 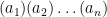 .
.  .
. 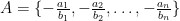 , even though not all of these quotients have to be rational. And if we want to find these values, we just have to search the set of quotients
, even though not all of these quotients have to be rational. And if we want to find these values, we just have to search the set of quotients  , where
, where 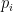 is a factor of
is a factor of  and
and 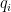 is a factor of
is a factor of  because that will check all of the values in
because that will check all of the values in 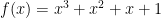 . This polynomial equals zero in three places (when
. This polynomial equals zero in three places (when  ). This definitely satisfies the theorem because
). This definitely satisfies the theorem because  . (Remember that the degree of a polynomial refers to the power of the highest degree term.)
. (Remember that the degree of a polynomial refers to the power of the highest degree term.) . First, we can note that
. First, we can note that  and
and  mod
mod  . So, in
. So, in  , where we consider the coefficients of
, where we consider the coefficients of  as being elements of
as being elements of  mod
mod 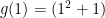 mod
mod 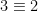 .
.  mod
mod 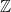 or
or 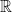 ).
).
 describes the angle that the dart’s path makes with the line.
describes the angle that the dart’s path makes with the line.  (slide over the stick figure a bit to the right).
(slide over the stick figure a bit to the right). ![\theta\in [-\frac{\pi}{2},\frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin+%5B-%5Cfrac%7B%5Cpi%7D%7B2%7D%2C%5Cfrac%7B%5Cpi%7D%7B2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) uniformly from the probability density function (PDF)
uniformly from the probability density function (PDF) ![\theta \sim U[-\frac{\pi}{2},\frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=%5Ctheta+%5Csim+U%5B-%5Cfrac%7B%5Cpi%7D%7B2%7D%2C%5Cfrac%7B%5Cpi%7D%7B2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) . This PDF has the equation
. This PDF has the equation  when
when ![x\in [-\frac{\pi}{2},\frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=x%5Cin+%5B-%5Cfrac%7B%5Cpi%7D%7B2%7D%2C%5Cfrac%7B%5Cpi%7D%7B2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and 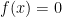 when
when  or
or  . This means that, for example, picking an angle between
. This means that, for example, picking an angle between 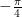 and
and 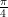 is just as likely as picking an angle between
is just as likely as picking an angle between  and
and 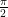 .
. 

 , and in the second triangle,
, and in the second triangle,  .
.  . There’s a
. There’s a  in the denominator since from all the way parallel to the number line facing to the left and all the way parallel to the number line facing to the right makes up
in the denominator since from all the way parallel to the number line facing to the left and all the way parallel to the number line facing to the right makes up 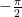 and
and  ). To get an appreciation for this, let’s first define the uniform probability distribution.
). To get an appreciation for this, let’s first define the uniform probability distribution.  , when
, when 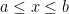 and
and  or
or  .
.  .
. 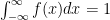 . Since we are supposing that
. Since we are supposing that  . The region over which we’d like to integrate has an infinitely long bottom side (given by the integration bounds). Since the height should be the same everywhere, any infinitely long rectangle (no matter how short), will have an infinite area.
. The region over which we’d like to integrate has an infinitely long bottom side (given by the integration bounds). Since the height should be the same everywhere, any infinitely long rectangle (no matter how short), will have an infinite area. 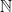 . Since every integer should be equally likely, this would mean that for any
. Since every integer should be equally likely, this would mean that for any  ,
,  , for some
, for some 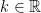 . Since there are infinitely many natural numbers, we would have to be able to evaluate
. Since there are infinitely many natural numbers, we would have to be able to evaluate 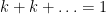 . But, no matter how small
. But, no matter how small  is, this sum will always grow without bound!
is, this sum will always grow without bound! 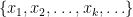 of real numbers is called Cauchy if for all
of real numbers is called Cauchy if for all  , there exists an
, there exists an  such that for all natural numbers
such that for all natural numbers 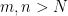 ,
,  .
.  ) where any two elements past that certain point will be closer together than the tolerance you chose.
) where any two elements past that certain point will be closer together than the tolerance you chose.  (for example,
(for example,  ) is complete if every Cauchy sequence with elements in
) is complete if every Cauchy sequence with elements in  is a sequence of nested closed intervals, which look something like this:
is a sequence of nested closed intervals, which look something like this: 
![\bigcap_{n=1}^{\infty} [A_n,B_n]](https://s0.wp.com/latex.php?latex=%5Cbigcap_%7Bn%3D1%7D%5E%7B%5Cinfty%7D+%5BA_n%2CB_n%5D&bg=ffffff&fg=000000&s=0&c=20201002) is non-empty. This property says that no matter how close you zoom in on the real number line, there will always be real numbers where you are looking.
is non-empty. This property says that no matter how close you zoom in on the real number line, there will always be real numbers where you are looking. ![\{[A_1,B_1],[A_2,B_2],\ldots\}](https://s0.wp.com/latex.php?latex=%5C%7B%5BA_1%2CB_1%5D%2C%5BA_2%2CB_2%5D%2C%5Cldots%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we’re simultaneously constructing two sequences of real numbers: One increasing sequence
, we’re simultaneously constructing two sequences of real numbers: One increasing sequence  , and one decreasing sequence
, and one decreasing sequence  .
.  ).
). of the nested sets will be nonempty!
of the nested sets will be nonempty! 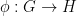 be a surjective homomorphism. Then
be a surjective homomorphism. Then  .
.  .
. 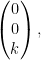 for any
for any  to
to  , to examine
, to examine 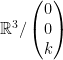 looks like. This is like asking, “what does everything in
looks like. This is like asking, “what does everything in  }.
}. : An
: An 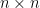 matrix
matrix  has only the solution
has only the solution  .
.  : The matrix
: The matrix  has rank
has rank  .
. The nullity of a matrix is the dimension of the null space.
The nullity of a matrix is the dimension of the null space.  Let
Let  .
.  ), since it maps onto
), since it maps onto  . This shows that if a matrix has full rank, then its null space is zero-dimensional, which connects the two statements of the IVT above.
. This shows that if a matrix has full rank, then its null space is zero-dimensional, which connects the two statements of the IVT above. 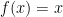 . That is, when you apply the function to that value, the value remains unchanged.
. That is, when you apply the function to that value, the value remains unchanged.  . When we multiply this matrix and vector, the vector remains unchanged. This also tells us that
. When we multiply this matrix and vector, the vector remains unchanged. This also tells us that 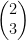 is an eigenvector of that matrix, and its corresponding eigenvalue is
is an eigenvector of that matrix, and its corresponding eigenvalue is  .
.  . When
. When 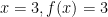 , since
, since  . Since the input
. Since the input 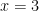 is unchanged after applying the function
is unchanged after applying the function 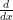 that takes in a function in
that takes in a function in 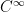 and outputs the function’s derivative, which is also in
and outputs the function’s derivative, which is also in  . The only function that satisfies this property is
. The only function that satisfies this property is  . This means that the function
. This means that the function  . We can add
. We can add  . Then we can rewrite this as
. Then we can rewrite this as 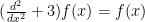 , making it clearer how solving this differential equation is the same as finding a fixed point of an operator.
, making it clearer how solving this differential equation is the same as finding a fixed point of an operator. 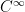 is a vector space. The sum of two smooth functions is smooth, if you scale a smooth function, it’s smooth, … Now, if we take for granted the fact that for any vector space, there exists a basis for it, it’s not too hard to see why the basis for the set of all smooth functions is infinite. If we just think about the set of all polynomials (which are a subset of all smooth functions), that set has an infinite basis (
is a vector space. The sum of two smooth functions is smooth, if you scale a smooth function, it’s smooth, … Now, if we take for granted the fact that for any vector space, there exists a basis for it, it’s not too hard to see why the basis for the set of all smooth functions is infinite. If we just think about the set of all polynomials (which are a subset of all smooth functions), that set has an infinite basis ( ). Since a subset of the set of all continuous functions has infinite dimension, the set of all continuous functions must also have an infinite dimension.
). Since a subset of the set of all continuous functions has infinite dimension, the set of all continuous functions must also have an infinite dimension. 