I want to connect the normal equations, which come up in statistics, to weak solutions, which come up in PDEs. Let’s start with the normal equations. These arise when you want to solve a linear system 

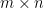
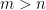



We can rearrange the normal equations and rewrite them as 

![(A[:,i],A\vec{x}-\vec{b}) = 0.](https://s0.wp.com/latex.php?latex=%28A%5B%3A%2Ci%5D%2CA%5Cvec%7Bx%7D-%5Cvec%7Bb%7D%29+%3D+0.&bg=ffffff&fg=000000&s=0&c=20201002)
Now, let’s talk about what a weak solution is. These usually come up when differential equations have solutions that might not be as differentiable as the equation itself requires. The idea behind weak solutions is to remove a bit of the strict requirement that a function be smooth enough, as long as it satisfies the other aspects of the PDE. If you wanted to solve a PDE of the form 




Using properties of bilinear forms, we can rewrite this equation as 
If we use the example of the linear system we started with, this says that 
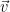
This looks identical to the result in the normal equations that ![(A\vec{x}-\vec{b},A[:,i]) = 0.](https://s0.wp.com/latex.php?latex=%28A%5Cvec%7Bx%7D-%5Cvec%7Bb%7D%2CA%5B%3A%2Ci%5D%29+%3D+0.&bg=ffffff&fg=000000&s=0&c=20201002)


This means that, in some ways, you can think of the least squares formulation of an overdetermined linear system as a weak formulation. In PDEs, weak formulations where the test functions are the same as the elements you’re using to approximate your solution (for least squares those are the columns of
So that means there’s a nice relationship between Galerkin finite element methods and the least square formulation of an overdetermined linear system!
 then
then  . Another way to say this is that, given a set of nonnegative numbers, their geometric mean is always less than or equal to their arithmetic mean.
. Another way to say this is that, given a set of nonnegative numbers, their geometric mean is always less than or equal to their arithmetic mean. , you get
, you get  . You can think of both sides of this as the area of an
. You can think of both sides of this as the area of an 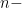 dimensional box. And this statement says that given sides lengths of a fixed sum, to maximize the volume of the box, you should make each side length the same. That side length is
dimensional box. And this statement says that given sides lengths of a fixed sum, to maximize the volume of the box, you should make each side length the same. That side length is  .
.  are nonnegative), then
are nonnegative), then  . The product of the eigenvalues of a matrix is
. The product of the eigenvalues of a matrix is  , and sum of the eigenvalues is
, and sum of the eigenvalues is  . That means we can write that inequality as
. That means we can write that inequality as  . We can raise both sides to the
. We can raise both sides to the  .
. be a nonlinear function. Then the Jacobian of this nonlinear transformation is
be a nonlinear function. Then the Jacobian of this nonlinear transformation is  . If the Jacobian matrix is positive semidefinite we can apply the inequality from earlier. It will tell us that
. If the Jacobian matrix is positive semidefinite we can apply the inequality from earlier. It will tell us that  . The right hand side of this can be rewritten as
. The right hand side of this can be rewritten as  , but this is the same thing as
, but this is the same thing as  , where
, where  is the divergence of a vector field. So we get that
is the divergence of a vector field. So we get that  . This is interesting because the determinant of a linear transformation essentially tells you the volume that its basis vectors occupy, and this inequality says that this quantity is bounded above by a function of
. This is interesting because the determinant of a linear transformation essentially tells you the volume that its basis vectors occupy, and this inequality says that this quantity is bounded above by a function of  .
.  behaves like a source or a sink at a point, so this inequality relates the volume occupied by the linearization of
behaves like a source or a sink at a point, so this inequality relates the volume occupied by the linearization of  is a convex function. Then the Hessian matrix
is a convex function. Then the Hessian matrix  is given by
is given by  is positive semidefinite. Therefore
is positive semidefinite. Therefore  . Like in the previous example, we can simplify the numerator. The trace of
. Like in the previous example, we can simplify the numerator. The trace of  , but this is just
, but this is just  , the Laplacian of
, the Laplacian of  . If you compute
. If you compute  at a critical point of the function
at a critical point of the function  ), you get the Gaussian curvature of the function at that point. That means that this inequality gives an upper bound on the Gaussian curvature at a critical point in terms of
), you get the Gaussian curvature of the function at that point. That means that this inequality gives an upper bound on the Gaussian curvature at a critical point in terms of 