In this post, we’re going to talk about logistic regression and how it connects to normal distributions. Normal distributions (or scaled/squished normal distributions) come up so frequently in statistics, but sometimes they’re kind of hidden in a problem and it’s hard to tell that they’re actually there. But we are going to find one.
We’re going to talk about logistic regression with a single independent variable and two possible outcomes because that’s easiest to visualize. The goal of logistic regression is to predict which of two outcomes is more likely given some piece of information about the independent variable.
Our running example will be that we want to predict whether someone is male or female based on their height. To do this, we’ll start by plotting peoples heights on the 
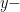



We’d like to figure out a way to guess if someone is a male or female based on their height. We do this by fitting a curve that estimates the probability that a person is male given their height. That will be a curve that looks like something like this:
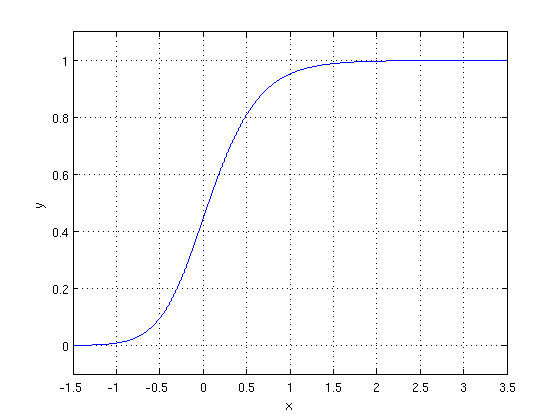
The place where the two populations overlap most corresponds to the region of the plot near 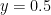
The idea is that when a new person comes along, you can look up their height on the
Now let’s talk about how this connects to the normal distribution. The logistic curve that we’re referencing gives us a way of estimating 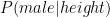
THE PROBABILITY BELLS ARE SOUNDING. We’re talking about a function whose
To figure out what what probability distribution function (PDF) this is the CDF for, we have to take the derivative of the CDF. That’s because for probability distributions with a single independent variable, the derivative of the CDF is the PDF.
That means we want to take the derivative of the logistic function to figure out the distribution (PDF) that this data came from. That function is the normal distribution!
That means that whenever you perform logistic regression with a single independent variable, you’re assuming that the dependent variable (heights in our case) were normally distributed!
After fitting a logistic regression model to our height data, we could decide some height cutoff (it turns out to be the average height), below which anyone with that height would be classified as female and above which anyone with that height would be classified as male.
What’s interesting is that this logistic regression model corresponds to a normal distribution of heights with the same cutoff.

So anyone with height below 66.368 inches would be classified as female, and anyone with height above 66.368 would be classified as male!
I just think it’s neat that the normal distribution comes up in this way!
